
Bu yazıda, popüler doküman veri tabanlarından Elasticsearch (ES) ile metin işleme ve sorgulama konusunda bazı önemli noktaları sizlerle paylaşmak istiyorum. Java da yazılmış olan açık kaynak kodlu metin arama motoru olan Apache Lucene kullanılarak geliştirilen Elasticsearch, rakibi Apache Solr ile ciddi bir rekabet içinde.
Bu yazı Türkçe kaynaklarda fazlaca değinilmediğini düşündüğüm, Elasticsearch ile metin verisinin işlenmesinin detaylarına bir giriş niteliğinde olacak. Özellikle bu alanda yabancı çözümlerin Türkçe metinlere uygun çözümler içerip içermediği konusunda kafa yormuş ve daha önceden metin işleme konusu ile ilgili geliştirme yapmış bir kişi olarak, Elasticsearch ü bu açıdan oldukça iyi bulduğumu söyleyebilirim.
Metin işlemenin temel adımları
Metnin hangi dilde olduğundan bağımsız olarak, metin işlemede temel adımlar parantez içinde ES dokümanlarında verilen isimleri ile birlikte şu şekildedir.
- Dilin ve mümkünse alanın belirlenmesi, Türkçe metin, spor, edebiyat, askeriye, sosyal medya alanı gibi. Bu kullanılacak referans bir corpus (derlem) kullanılarak yapılacak sonraki adımlardaki işlemler için gereklidir.
- Metnin kelimelere ayrıştırılması, (tokenization).
- Fazlalık olan işaretlemelerin ve gereksiz kelimelerin temizlenmesi (stopwords),
- Kalan kelimelerin standartlaştırılması ve kökünün bulunması, (normalization, stemming)
- Kelimelerin benzer olanlarının tespit edilmesi, (synonyms)
- Hatalı kelimelerin düzeltilmesi (typoes and mispellings)
- Uygun şekilde saklanması (indexing)
Bu işlemler hangi dilde olursa olsun bütün metin işlemelerde geçerlidir ve hazır bir kütüphane kullanılarak metin işlemesi yapıldığında farkında olarak ya da olmadan bu adımlar gerçekleştirilmektedir. Bu açıdan bakıldığında Elasticsearch ün gayet açık ve anlaşılır bir işleme mantığı olduğunu ve kullanıcıya yapacağı metin işlemede ciddi kolaylıklar sunarak bu karmaşık işlemi başlangıç (default) değerler ile yapabilmesini sağladığı görülüyor.
Tabii burada ilk kullanıcı için ciddi avantaj olan bu durum, ileri seviyede kullanım için bu default değerlerin nasıl değiştirileceğinin öğrenilmesi gerektiği anlamına gelmektedir. Şimdi bu adımların Elasticsearch ile nasıl gerçekleştirildiğine yakından bakalım.
Dilin ve mümkünse alanın belirlenmesi
Öncelikli olarak dil ve mümkünse bir alan (domain) belirlenmelidir. Bunun nedeni metin işlenirken kullanılacak korpus un seçilmesinin buna bağlı olmasıdır. Korpus, bir dilde yazılmış eserlerde çıkabilecek her kelimenin sistematik olarak tutulduğu bir katalogdur. Bu kataloğa bakarak bir kelimenin o dilde olmadığı, yanlış yazıldığı, cümle başında veya sonunda olamayacağı tespiti yapılabilir. Dilimiz için somut bir örnek için Türkçe korpus a bakılabilir.
Dokümanın yazıldığı dilin tespitinde iki ayrı yöntem kullanılmaktadır ve Elasticsearch de bu iki yöntemi kullanıcıya sunmaktadır. Birincisi bir standart dil belirlenip konfigürasyon buna göre yapılır ve eğer bunun dışında bir dil olacaksa bir parametre ile bildirilir. Özellikle çok dilli metinlerle uğraşanlar için otomatik metin dili belirlemek bir zorunluluk haline geldiğinden, Elasticsearch ün bu tür durumlarda önerdiği açık kaynak kodlu proje chromium-compact-language-detector değişik dilleri desteklemektedir. Bunun dışında, kullanıcı ekrandan bir metin giriyorsa uygulama içinden HTTP accept-language başlık parametresi dili belirlemek için kullanılabilir. Detayları olan bir konudur. Alanın belirlenmesi metni işlerken korpusun daraltılması açısından bazı faydalar sağlamaktadır, zorunlu değildir. Özellikle sorgu performansında iyileşme sağlar.
ElasticSearch e verinin aktarımı
Metni Elasticsearch e koymak, Elasticsearch ün terminolojisinde indekslemek anlamına gelmektedir. Bunun nedeni metni kaydederken yukarıdaki ikinci adımdan yedinci adıma kadarki süreçte kelimeleri ayrıştırma, fazlalıkları atma gibi işlemler ile her bir kelimeye bir indeks karşılık getirilmesidir. Oluşturulan bu indekse inverted index denmektedir.
Basit bir şekilde şöyle açıklayabiliriz. Tabloda ilk sütuna kelimeleri yazıyoruz, her bir doküman için bir sütun ekliyoruz ve her bir kelimenin karşısına o dokümanda olup olmadığı bilgisini bir bit ile 1/0 ile belirtiyoruz.
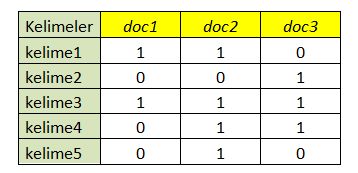
Bütün bu işlemler sorgulama sırasında hızlı cevap vermek ve sorguya uygun doküman listesini kullanıcıya dönmek içindir. Bu nedenle bu noktada Elasticsearch de normalde kullanılan bilgi erişim yöntemine kısaca değinmekte fayda görüyorum. Sorgulamalarda sorguda geçen kelimeler bir bilgi erişimi metodu olan Boolean Model kullanılarak inverted index yardımı ile ilişkili dokümanları getirir. Bu model ‘ve’, ‘veya’ ve ‘değil’ gibi mantıksal operatörleri kullanmaya izin vererek basit bir şekilde indeks tablosundaki hangi dokümanların sorguya uyduğunu hızlı bir şekilde bulur.
Sorgu : (Kelime1 ve kelime3) veya kelime 5
Cevap : doc1, doc2
Doc3 ün dönmemesinin sebebi kelime1 in doc3 de bulunmamasıdır. Kelime5 doc1 de bulunmasa bile veya ile bağlandığı için cevap içinde bulunuyor.
Bu aşamada özellikle sonuçların sayısının çok olduğu durumlarda sonuçların kullanıcıya sunulacağı sıranın ne olacağı önem kazanmaktadır. Örneğin çoğumuz arama motorundan sorduğumuz soruya dönen cevaplardan ilk on veya yirmi cevaba bakarız. Bunun için Elasticsearch, Lucene ın altyapısını da kullanarak, çok karmaşık hesaplamalar yaparak _score parametresindeki [0, 1] aralığındaki değerleri üretir. İlişiklik (relevance) değerleri olarak nitelendireceğimiz bu değerlerin nasıl hesaplandığını bilmek, istenen sorgu kalitesinin nasıl arttırılacağının da cevabıdır. Şimdi bu değerin nasıl hesaplandığına bakalım.
İlişiklilik (relevance) değeri
Yapılan bir sorgu ile var olan dokümanlardan hangilerinin kullanıcıya döndürülmesi gerektiğine karar vermek hatta sıralamak için doküman veri tabanlarında kullanılan algoritmalar, bu iş için kullanılan ilişkisel veri tabanlarından benzer etkin sonuçların alınamamasının temel sebeplerinden belki de en önemlisidir. Şimdi perdenin arkasına kısa bir bakış yapalım. Her kelime için hesaplanan aşağıdaki üç değer bu konuda öne çıkmaktadır.
a) Terim frekansı (tf)
Sorgudaki kelimelerden biri dokümanda altı kere geçiyorsa bir kere geçen dokümana göre altı kere geçen doküman daha ilişkili kabul edilir. T terim veya kelime, d doküman veya alan olmak üzere;
tf(t in d) = √frekans
b) Ters doküman frekansı (idf)
Ters doküman frekansı (inverse document frequency – idf) kelimelerin koleksiyondaki dokümanlar içinde geçme sıklığını ifade eden bir değerdir.
Kelime ne kadar çok dokümanda geçiyorsa o kadar ayırt edici özelliği zayıftır kabulüne dayanır. Bu nedenle idf değeri ne kadar küçük ise kelimenin o kadar ağırlığı arttırılır. Ne kadar büyükse o kadar düşürülür. idf in tam değeri şu formül ile hesaplanır.
idf(t) = 1 + log ( numDocs / (docFreq + 1))
c) Alan uzunluğu kuralı (norm)
Dokümanın veya alanın uzunluğu ne kadar fazla ise kelimenin o dokümanda bulunmasının önemi o kadar azalır. Bu açıdan, başlıkta geçen bir kelime konuda geçen bir kelimeden daha önemlidir.
norm(d) = 1 / √numTerms
Bu değerlerin hesaplanması, doküman Elasticsearch e ilk kaydedilirken indeksleme aşamasında yapılır. Bir kelime için hesaplanan bu üç değer kullanılarak bir skor üretilmesi ve hatta birçok sorguda olduğu gibi birden fazla terim içeren sorgular için de bu işlemin yapılması için Elasticsearch de şu yöntem uygulanmaktadır. Bulunan bu değerler ile oluşturulan vektörler kullanılarak, ilişiklik problemi vektör uzaylarında vektörlerin birbiri arasındaki açıyı bulma problemine dönüştürülmektedir. Bu şekilde sorgudan üretilen vektör ile her bir dokümanın vektörü çok boyutlu uzayda vektör hesaplamaları yapılarak skorlar bulunmaktadır. Bu hesaplamalar Lucene ın Pratik Skorlama fonksiyonuna girdi olmaktadır. Detay için bu linke bakabilirsiniz.
Sorgu performansının arttırılması
Yukarıdaki bilgiler bazıları için fazla detay gibi gelecektir ama bilmemiz gereken _score parametresinin hesaplanmasında nelerin etkin olduğu ve bunları sorgu sonuçlarının kalitesini arttırmak için nasıl kullanabileceğimizdir. Bu bilgilere dayanarak Elasticsearch de sorgu performansının arttırılması için ilk akla gelenlerden bazıları şunlardır.
- Eş anlamlı kelimelerin tanıtılması önemlidir. Bu şekilde terim frekansı arttırılabilir.
- Kelimelerin normalize edilmesi önemlidir. Dokümanların çoğunda geçmesi beklenen zamirler bu, şu, soru ekleri ‘mı’, ‘mü’, ‘mıdır’ gibi sorguda faydalı olmayacağı düşünülen kelimelerin indekslemeye sokulmaması genellikle önerilir.
- Alan uzunluğunun, dokümanlarda sıkça geçen ‘ve’, ‘veya’ gibi indekslemede gereksiz kelimelerin atılması ile azaltılması iyidir.
Uygulama
Esasen bu noktaya kadar anlattıklarımız metin işlemesi yapan herhangi bir çözümün yaptıkları olarak görülebilir. Bu noktada Elasticsearch ile nasıl yapıldığı konusunda somut örnekler vermek istiyoruz.
Ortam
İşlemler için kullandığımız ortamı kısaca anlatırsak, tek node üzerinde dağıtıklık özelliğine girmeden default ayarları kullanarak Ubuntu üzerinde yaptığımız bir Elasticsearch 1.7.1 kurulumuüzerinden anlatıyoruz. Elasticsearch ile etkileşimleri REST API ile gerçekleştiriyoruz. Alternatiflerimiz
- Bir web browser ile
- komut satırından curl komutu ile
- Marvel/Sense ile plug-in yüklenirse bir browser yardımı ile web sayfasından. Marvel/Sense i anlatan türkçe bir kaynak
- Herhangi bir browser ın restclient addon u, örnek; firefox restclient
Basit sorgular için doğrudan bir browser ile sorgulamalarımızı yapabiliriz ama kompleks sorgular için kendi sorgulama dili olanQuery DSL (Domain Spesific Language) kullanılıyor. Bu dil JSON formatına bağlı kalınarak hazırlanmış yazım kuralları içeriyor. Çok karmaşık sorgular yapmaya izin veriyor.
Analyzer
Yukarıda detaylı bahsettiğimiz kelimelerin işlenmesi sürecinde Elasticsearch analyzer denen bir paket kullanır. Dilin ve yapılacak işlemin durumuna göre alternatifler mevcut olmakla birlikte default olarak standard anayzer kullanılır ve index default olarak analyzedolarak alınınır. Bunun anlamı ilgili alan yukarıdaki işlemlere tabi tutuldu ve indeksleme buna göre yapıldı demektir. Bazı durumlarda not analyzed yapılması gerekebilir. Özellikle işlenmemesi aynen alınması gereken alanlar için bu yöntem önerilir.
Öncelikle default analyzer ın ihtiyacımızı karşılayıp karşılamadığını anlamak, alternatif anlayzer seçimini yapmamızı kolaylaştıracak alet olarak Analyze API sini kullanabiliriz.
Deafult analyzer
Örnek metin ‘Bu gözümün nuru türkçenin hali ne olacak’ olsun.
curl -XGET ‘localhost:9200/_analyze?analyzer=standard‘ -d ‘Bu gözümün nuru türkçenin hali ne olacak’
Elasticsearch string bir alan tespit ettiğinde onu full text string olarak ele alır ve default olarak standard analyzer ı kullanır. Bu komut çalıştırıldığında kelimelere ayrıştırılma işlemi yapılır, metinde kelimenin nerede başlayıp nerede bittiği bilgisi ile birlikte tespit edilir ve indeksleme buna göre yapılır.
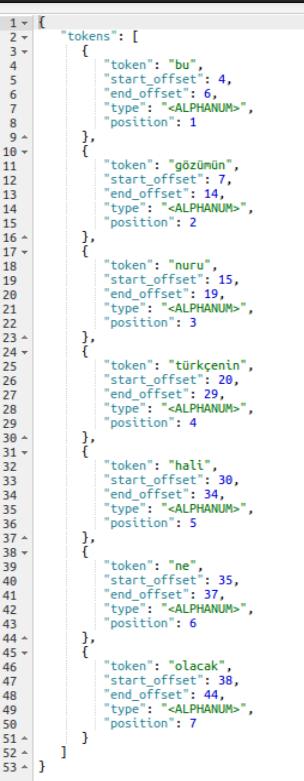
Burada <türkçenin> kelimesi yerine <türkçe>, <gözümün> kelimesi yerine <göz> kelimelerinin indekslenmesini isteyebiliriz. Hatta <bu> kelimesinin ayırt edici bir özelliği olmadığından tamamen kaldırılmasını isteyebiliriz. Burada ayırt edici özellik olarak metinlerin çoğunda ve yüksek frekansta geçen kelimelerin dokümanları indekslemede kullanılmamasının genellikle daha iyi sonuç ürettiğini söylemek istiyoruz.
Bu durumda farklı bir analyzer kullanmak isteyebiliriz. Bunun için built-in olanları kullanabilir veya kendimiz custom bir analyzer tanımlayabiliriz. Biz var olan turkish anayzer ı kullanalım.
Turkish analyzer
Türkçe için özel olarak geliştirilmiş built-in bir analyzer kullanalım.
curl -XGET ‘localhost:9200/_analyze?analyzer=turkish‘ -d ‘Bu gözümün nuru türkçenin hali ne olacak’

Artık <bu> ve <ne> kelimeleri indekslenmedi. <türkçenin> yerine <türkçe>, <gözümün> yerine <göz> kelimeleri indekslendi. Bu şekilde sorgu performansı da artmış oldu.
Analyzer seçiminin sorgu performansına etkisi
Bu aşamada örnek için kullandığımız metni Elasticsearch ile indeksleyip yani kaydedip sonrasında analyzer seçiminin sorgularımızın sonuçlarına nasıl yansıdığına bakalım.

36. satırdaki sorgu ile
GET /turkcedoc/denemeler/_search?q=metin1:türkçe
sorgulama yaptığımızda sorgu sonucu boş geliyor. Bu indekslenen kelimenin birebir aranmasından kaynaklanıyor. Çünkü <Türkçenin> kelimesi indekslenmişti. Bu tip durumlarda fuzzy matching kullanılabilir. Bu durumda 38. satırdaki sorgu ile cevabı alıyoruz.
GET /turkcedoc/denemeler/_search?q=metin1:türkçenin
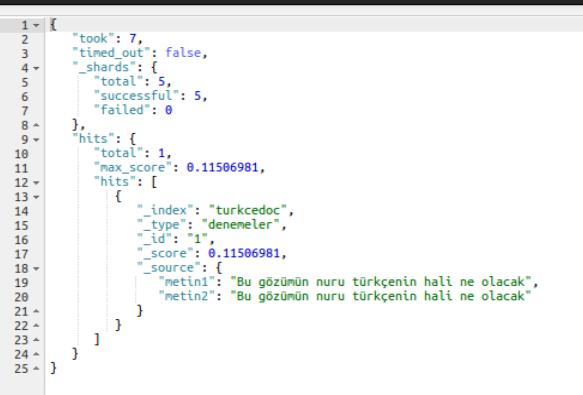
Gelen sonuçta _score değerine bakarsak uygunluğun 0.11506981 ile değerlendiğini görüyoruz.
40.satırdaki sorguyu yapalım
GET /turkcedoc/denemeler/_search?q=metin2:türkçenin
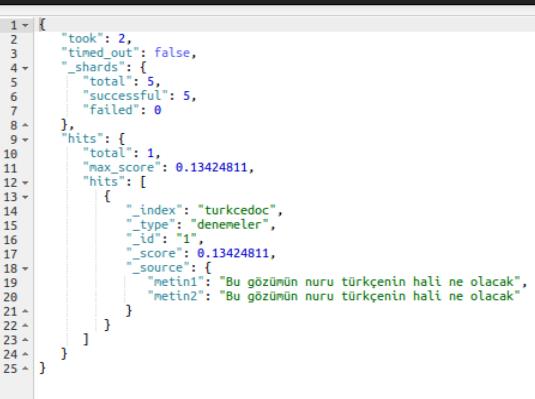
Bu kez sonucun _score değerinde artış olduğunu görüyoruz. 0.13424811 Bu küçük gibi görünen artış binlerce dokümanın olduğu bir ortamda diğerlerinin önüne geçmek için yeterlidir. Hatta bu kez
GET /turkcedoc/denemeler/_search?q=metin2:türkçe
sorgusuna da cevap alıyoruz.
Yazıyı daha fazla uzatmamak için analyzer ın bize sunduğu olanaklardan birçoğuna burada yer veremiyorum. Sonuç olarak gerçekten sorgu sonuçlarını ilgilendiren indeksleme işlemlerinin arka planının anlaşılmasının ve analyzerı buna göre geliştirip değiştirmenin getirdiği faydaları anlatabildiğimi umuyorum. Belki başka bir yazıda diğer özellikleri de ele alabiliriz.
Yorumlar